- 本文为Hive入门篇,主要记录Hive安装配置,数据存储和表操作。
学习资料汇总
Overview
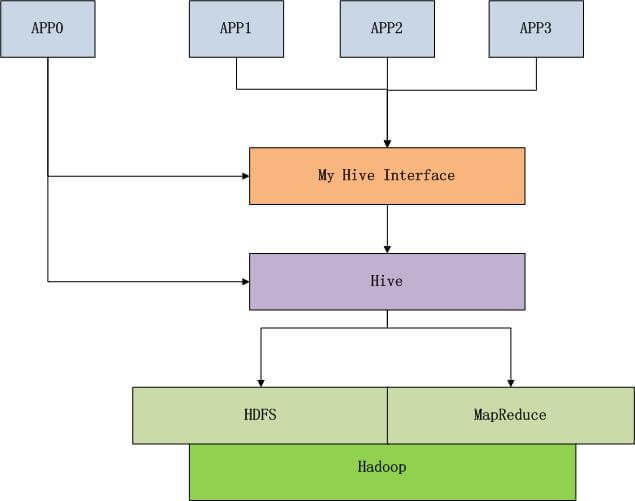
Hive是建立在 Hadoop 上的数据仓库基础构架。
Hive 是 Hadoop 家族中一款数据仓库产品,Hive 最大的特点就是提供了类 SQL 的语法,封装了底层的 MapReduce 过程,让有 SQL 基础的业务人员,也可以直接利用 Hadoop 进行大数据的操作。就是这一个点,解决了原数据分析人员对于大数据分析的瓶颈。
Hive 可以将结构化的数据文件映射为一张数据库表,并提供完整的 SQL 查询功能,可以将 SQL 语句转换为 MapReduce 任务运行。Hive 定义了简单的类 SQL 查询语言,称为 HQL。
Hive 的知识图谱如下图所示。

Hive 已经用类 SQL 的语法封装了 MapReduce 过程,这个封装过程就是 MapReduce 的标准化的过程。
我们在做业务或者工具时,会针对场景用逻辑封装,这里的第2层封装是在Hive之上的封装。在第2层封装时,我们要尽可能多的屏蔽 Hive 的细节,让接口单一化,低少灵活性,再次精简 HQL 的语法结构。只满足我们的系统要求,专用的接口。
在使用二次封装的接口时,我们已经可以不用知道 Hive 是什么, 更不用知道 Hadoop 是什么。只需要知道,SQL查询(SQL92标准),怎么写效率高,怎么写可以完成业务需要就可以了。
当我们完成了 Hive 的二次封装后,我们可以构建标准化的 MapReduce 开发过程。
Hive 不适合用于联机(online)事务处理,也不提供实时查询功能。它最适合用在基于大量不可变数据的批处理作业。Hive特点是可伸缩(在Hadoop的集群上动态地添加设备),可扩展,容错,输入格式的松散耦合。
Hive 的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
Hive和关系型数据库的区别
Hive 在很多方面与传统关系数据库类似(例如支持 SQL 接口),但是其底层对 HDFS 和 MapReduce 的依赖意味着它的体系结构有别于传统关系数据库,而这些区别又影响着 Hive 所支持的特性,进而影响着 Hive 的使用。
下面列举一些简单区别
- Hive 和关系数据库存储文件的系统不同,Hive 使用的是 Hadoop 的HDFS(Hadoop的分布式文件系统),关系数据库则是服务器本地的文件系统
- Hive 使用的计算模型是 MapReduce,而关系数据库则是自己设计的计算模型
- 关系数据库都是为实时查询的业务进行设计的,而 Hive 则是为海量数据做数据挖掘设计的,实时性很差;实时性的区别导致 Hive 的应用场景和关系数据库有很大的不同
- Hive 很容易扩展自己的存储能力和计算能力,这个是继承 Hadoop 的,而关系数据库在这个方面要差很多
Hive 安装配置
Hive 安装参考资料如下
- Mac 上 Hive 环境搭建 | blog
- MacOS 下hive的安装与配置 | 知乎
- Hive安装及使用攻略 | 粉丝日志
- mac下Hive+MySql环境配置 | blog
- Mac Hive 配置和安装 | 简书
此处,简单记录Hive的安装和配置步骤
安装mysql
- 通过 Homebrew 安装 mysql
1 | brew install mysql |
安装结束后,会有如下提示
1 | We've installed your MySQL database without a root password. To secure it run: |
上述信息提示,
- 运行
brew services start mysql,可以在后台启动 mysql - 运行
mysql.server start,可以在前台启动 mysql(关闭控制台,服务停止) - 运行
mysql_secure_installation,可以进行密码设置
- 使用
mysql --version校验 mysql 版本号
1 | mysql --version |
- 设置mysql秘密,设定密码为
mysql113459
1 | brew services start mysql //设定密码前需要先启动mysql |
MySQL 新版本中引入了密码安全级别的概念,设置低强度的密码有时会被禁止。为此可以直接指定密码安全强度,执行下述命令。
1 | mysql> set global validate_password_policy=0; //设置密码强度级别为low |
若执行 SHOW VARIABLES LIKE 'validate_password%'; 遇到 Unknown system variable 'validate_password_policy' 报错信息,可以参考 MySQL validate_password_policy unknown system variable | StackOverflow 进行处理。
This problem has happened because validate_password plugin is by default NOT activated.
1 | mysql> select plugin_name, plugin_status from information_schema.plugins where plugin_name like 'validate%'; |
- mysql启动
1 | brew services start mysql //后台启动 |
- mysql关闭
1 | sudo mysql.server stop |
- mysql重启
1 | sudo mysql.server restart |
- 查看默认数据库
1 | mysql -u root -p //密码 mysql113459 |
Hive 安装
- 通过 Homebrew 安装 Hive
1 | brew install hive |
安装结束后,会有如下提示
1 | ==> Caveats |
- 使用
hive --version校验 hive 版本号
1 | lbsMacBook-Pro:~ lbs$ hive --version |
- hive 环境变量配置
(1) 打开配置文件
1 | vim ~/.bash_profile |
(2) 更新配置文件
1 | HIVE_HOME=/usr/local/Cellar/hive/3.1.2 |
(3) 使配置文件生效
1 | source ~/.bash_profile |
修改 Hive 默认元数据库
默认情况下,Hive 元数据保存在内嵌的 Derby 数据库中,只能允许一个会话连接,只适合简单的测试。实际生产环境中不使用,为了支持多用户会话,则需要一个独立的元数据库,可以使用 MySQL 作为元数据库,Hive 内部对 MySQL 提供了很好的支持。
- Hive 默认元数据库是 derby。为了方便,这里给出用 mysql 储存元数据的配置
1 | //创建数据库metastore |
Hive 配置
- 进入 Hive 的安装目录,创建
hive-site.xml文件
1 | $ cd /usr/local/Cellar/hive/3.1.2/libexec/conf |
在配置文件中,对以下几个属性进行修改。
1 | <property> |
- 拷贝
mysql-connector到 hive 的安装目录下
1 | $ curl -L 'http://www.mysql.com/get/Downloads/Connector-J/mysql-connector-java-8.0.15.tar.gz/from/http://mysql.he.net/' | tar xz |
- 初始化 metastore 数据库
目前直接查看 metastore 数据库,可以发现数据库是空的。
1 | mysql> show databases; |
在命令行模式(非mysql CLI)下执行下述命令,初始化 metastore 数据库
1 | $ schematool -initSchema -dbType mysql |
执行完毕后,再次查看数据库,会发现如下信息
1 | mysql> show tables; |
启动 Hive
启动Hive前,需要先运行Hadoop。之后运行 hive 或者 hive shell 可以进入Hive Shell
1 | hive |
可视化工具 DbVisualizer
- DbVisualizer Software
- DbVisualizer User Guide
- Installing a JDBC Driver
- Supported databases and JDBC drivers Download
- 在mac上DbVisualizer图形化客户端配置连接Hive | Blog
- hive-jdbc-uber-jar | github
下载
dbvis_macos_11_0_jre.dmg并执行安装也可以下载
.tar.gz包进行安装
1 | gunzip dbvis_unix_11_0.tar.gz |
- 点击 Docker 中 DbVisualizer图标启动,或使用如下脚本启动
1 | DbVisualizer/dbvis.sh |
- 从 hive-jdbc-uber-jar | github 下载
hive-jdbc-uber-jar,放置到/Users/lbs/.dbvis/jdbc路径下,并导入到 DbVisualizer 配置中
- 在 DbVisualizer 的偏好设置中的
Specify overridden Java VM Prperties here中添加如下设置
1 | -Dsun.security.krb5.debug=true |
Hive交互式模式 CLI
运行 hive 或者 hive shell 可以进入Hive Shell。Hive的交互模式遵循下述规则。
quit,exit: 退出交互式shellreset: 重置配置为默认值set <key>=<value>: 修改特定变量的值(如果变量名拼写错误,不会报错)set: 输出用户覆盖的 hive配置变量set -v: 输出所有Hadoop和Hive的配置变量add FILE[S] *,add JAR[S] *,add ARCHIVE[S] *: 添加 一个或多个 file, jar, archives到分布式缓存list FILE[S],list JAR[S],list ARCHIVE[S]: 输出已经添加到分布式缓存的资源list FILE[S] *,list JAR[S] *,list ARCHIVE[S] *: 检查给定的资源是否添加到分布式缓存delete FILE[S] *,delete JAR[S] *,delete ARCHIVE[S] *: 从分布式缓存删除指定的资源! <command>: 从 Hive shell 执行一个 shell 命令dfs <dfs command>: 从 Hive shell 执行一个 dfs 命令<query string>: 执行一个 Hive 查询,然后输出结果到标准输出source FILE <filepath>: 在 CLI 里执行一个 hive 脚本文件!clear;: 清除命令行show tables;: 展示数据表desc tableName:展示一个数据表的结构
和SQL类似,HiveQL一般是大小写不敏感的(除了字符串比较以外),因此 show tables; 等同于 SHOW TABLES;。制表符(Tab)会自动补全 Hive 的关键字和函数。
下面给出一个简单的 Hive Shell 操作 Demo,详情参考 Hive安装及使用攻略 | 粉丝日志。
- 创建本地数据文件(文本以tab分隔)
1 | ~ vi /home/cos/demo/t_hive.txt |
- 进入Hive Shell,创建新表
1 | #创建新表 |
- 查看表
1 | hive> show tables; |
- 正则匹配表名
1 | hive>show tables '*t*'; |
- 查看表数据
1 | hive> select * from t_hive; |
- 查看表结构
1 | hive> desc t_hive; |
- 修改表,增加一个字段
1 | hive> ALTER TABLE t_hive ADD COLUMNS (new_col String); |
- 删除表
1 | hive> DROP TABLE t_hadoop; |
Beeline
HiveServer2
Hive 内置了 HiveServer 和 HiveServer2 服务,两者都允许客户端使用多种编程语言进行连接,但是 HiveServer 不能处理多个客户端的并发请求,所以产生了 HiveServer2。
HiveServer2(HS2)允许远程客户端可以使用各种编程语言向 Hive 提交请求并检索结果,支持多客户端并发访问和身份验证。HS2 是由多个服务组成的单个进程,其包括基于 Thrift 的 Hive 服务(TCP 或 HTTP)和用于 Web UI 的 Jetty Web 服务器。
HiveServer2 拥有自己的 CLI(Beeline),Beeline 是一个基于 SQLLine 的 JDBC 客户端。由于 HiveServer2 是 Hive 开发维护的重点 (Hive0.15 后就不再支持 hiveserver),所以 Hive CLI 已经不推荐使用了,官方更加推荐使用 Beeline。
Beeline 参数
Beeline 拥有更多可使用参数,可以使用 beeline --help 查看,完整参数如下
1 | // ... |
在 Hive CLI 中支持的参数,Beeline 都支持,常用的参数如下。更多参数说明可以参见官方文档 Beeline Command Options。
| 参数 | 说明 |
|---|---|
| -u |
数据库地址 |
| -n |
用户名 |
| -p |
密码 |
| -d |
驱动 (可选) |
| -e |
执行 SQL 命令 |
| -f |
执行 SQL 脚本 |
例如,使用用户名和密码连接 Hive
1 | // $ beeline -u jdbc:hive2://localhost:10000 -n username -p password |
Ambari
和Hive进行交互的方式主要有2种:命令行和Ambari视图。
就 Ambari 的作用来说,就是创建、管理、监视 Hadoop 的集群,但是这里的 Hadoop 是广义,指的是 Hadoop 整个生态圈(例如 Hive,Hbase,Sqoop,Zookeeper 等),而并不仅是特指 Hadoop。用一句话来说,Ambari 就是为了让 Hadoop 以及相关的大数据软件更容易使用的一个工具。
Ambari 自身也是一个分布式架构的软件,主要由两部分组成:Ambari Server 和 Ambari Agent。简单来说,
- 用户通过 Ambari Server 通知 Ambari Agent 安装对应的软件
- Agent 会定时地发送各个机器每个软件模块的状态给 Ambari Server
- 最终这些状态信息会呈现在 Ambari 的 GUI,方便用户了解到集群的各种状态,并进行相应的维护
Hive实战Demo
Hive架构
尽管Hive使用起来类似SQL,但它仍然不是SQL,尤其体现在处理速度方面。底层的Hive查询仍然是以 MapReduce 作业的形式运行。MapReduce是批处理,而SQL则是一种交互式处理语音。
HCatalog
HCatalog 提供了一个统一的元数据服务,允许不同的工具如 Pig、MapReduce 等通过 HCatalog 直接访问存储在 HDFS 上的底层文件。
HCatalog 本质上是数据访问工具(如Hive或Pig)和底层文件之间的抽象层。
Hive 数据类型
基本数据类型
- tinyint/smallint/int/bigint:整数类型
- float/double:浮点数类型
- boolean:布尔类型
- string:字符串类型
string 类型下又包括 变长字符串 VARCHAR 和 定长字符串 CHAR。下面给出例子,说明两者区别
1 | hive > create table test1 |
上述例子中,varchar(20) 表示最大长度为20,实际长度可能不足20。char(20) 表示长度固定为20。
复杂数据类型
- Array:数组,由一系列相同数据类型的元素组成
- Map:集合,包含
key->value键值对,可以通过key来访问元素 - Struct:结构类型,可以包含不同数据类型的元素,这些元素可以通过 “点语法” 的方式访问
1 | hive> create table student |
时间类型
- Date:从 Hive 0.12.0 开始支持
- Timestamp:从 Hive 0.8.0 开始支持
Hive 文件格式
Hive 支持4种文件格式
TextFile(默认格式):基于行列混合的思想SequenceFile:基于行存储RCFile:基于行存储- 自定义
基于 HDFS 的行存储具备快速数据加载和动态负载的高适应能力,因为行存储保证了相同记录的所有域都在同一个集群节点。但是它不能满足快速的查询响应时间的要求,因为当查询仅仅针对所有列中的少数几列时,他就不能跳过不需要的列,直接定位到所需的列。此外,行存储也不易获得一个较高的压缩比。
TextFile
TextFile 是默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合 Gzip,Bzip2使用。但使用这方式,Hive 不会对数据进行切分,从而无法对数据进行并行操作。
SequenceFile
SequenceFile 是Hadoop API 提供的一种二进制文件支持,其具有使用方便,可分割,可压缩的特点。 SequenceFile 支持三种压缩选择:NONE, RECORD, BLOCK。RECORD 压缩率较低,一般建议使用 BLOCK 压缩。
RCFile
RCFile 是 Facebook 开发的一个集行存储和列存储的优点于一身,压缩比更高,读取列更快。
RCFile 存储结构遵循“先水平划分,再垂直划分”的设计理念。RCFile保证同一行的数据位于同一节点,因此元组重构的开销很低。其次,像列存储一样,RCFile 能够利用列维度的数据压缩,并且能跳过不必要的列读取。
在 RC File 的基础上,进一步改进,引入了 ORC (
Optimized Record Columnar),ORC 主要在压缩编码、查询性能上进行了升级。
自定义文件格式
当用户的数据文件格式不能被当前Hive识别的时候,可以自定义文件格式,通过实现 InputFormat 和 OutputFormat 自定义输入/输出格式。
Hive的数据存储
Hive 的存储是建立在 Hadoop 文件系统之上的。Hive 本身没有专门的数据存储格式,也不能为数据建立索引,因此用户可以非常自由地组织 Hive 中的表,只需要在创建表的时候告诉 Hive 数据中的列分隔符就可以解析数据了。
例如,打开 http://localhost:50070/,选择顶部分类栏中的 Utilities -> Browse the file system,可以查看到 Hive 中创建的数据库表对应的文件(存储在 /user/hive/warehouse 路径下)。

Hive的数据模型
Hive 中主要包括 4 种数据模型
- 表(Table)
- 外部表(External Table)
- 分区(Partition)
- 桶(Bucket)
Hive 的表和数据库中的表在概念上没有什么本质区别,在 Hive 中每个表都有一个对应的存储目录。而外部表指向已经在 HDFS 中存在的数据,也可以创建分区。
Hive 中的每个分区都对应数据库中相应分区列的一个索引,但是其对分区的组织方式和传统关系数据库不同。
桶在指定列进行 Hash 计算时,会根据哈希值切分数据,使每个桶对应一个文件。
表
表可以细分为
- Table 内部表
- Partition 分区表
- External Table 外部表
- Bucket Table 桶表
视图 View
- 视图是一种虚表,是一个逻辑概念,Hive 暂不支持物化视图
- 视图可以跨越多张表
- 视图建立在已有表的基础上,视图赖以建立的这些表称为基表
- 视图可以简化复杂的查询
- 视图 VIEW 是只读的,不支持
LOAD/INSERT/ALTER。可以使用ALTER VIEW改变 VIEW 定义 - Hive 支持迭代视图
Hive 数据操作
在执行操作前,请确保
localhost:50070页面访问到的Live Node个数大于0。
向表中装载数据
Demo-Insert插入数据
- 创建
hiveDemo数据库并使用该数据库
1 | create datbase IF NOT EXISTS hiveDemo; |
- 建表/查看/删除 数据表
1 | hive> Create Table golds_log(user_id bigint, accounts string, change_type string, golds bigint, log_time int); |
- 使用
Insert...Values语句写入数据
1 | hive> Insert into table golds_log values |
正常情况下可以看到下面的结果输出,说明在执行 Insert...values 语句时,底层是在执行 MapReduce 作业。
1 | Query ID = lbs_20200422053833_55b98d5a-ba4c-470d-909a-098213d1d937 |
此时在 http://localhost:50070/ 页面查看 Utillities -> Browser the file system,在 /user/hive/warehouse/hivedemo.db/golds_log 路径下可以看到一个 000000_0 的文件,下载到本地,查看其内容为
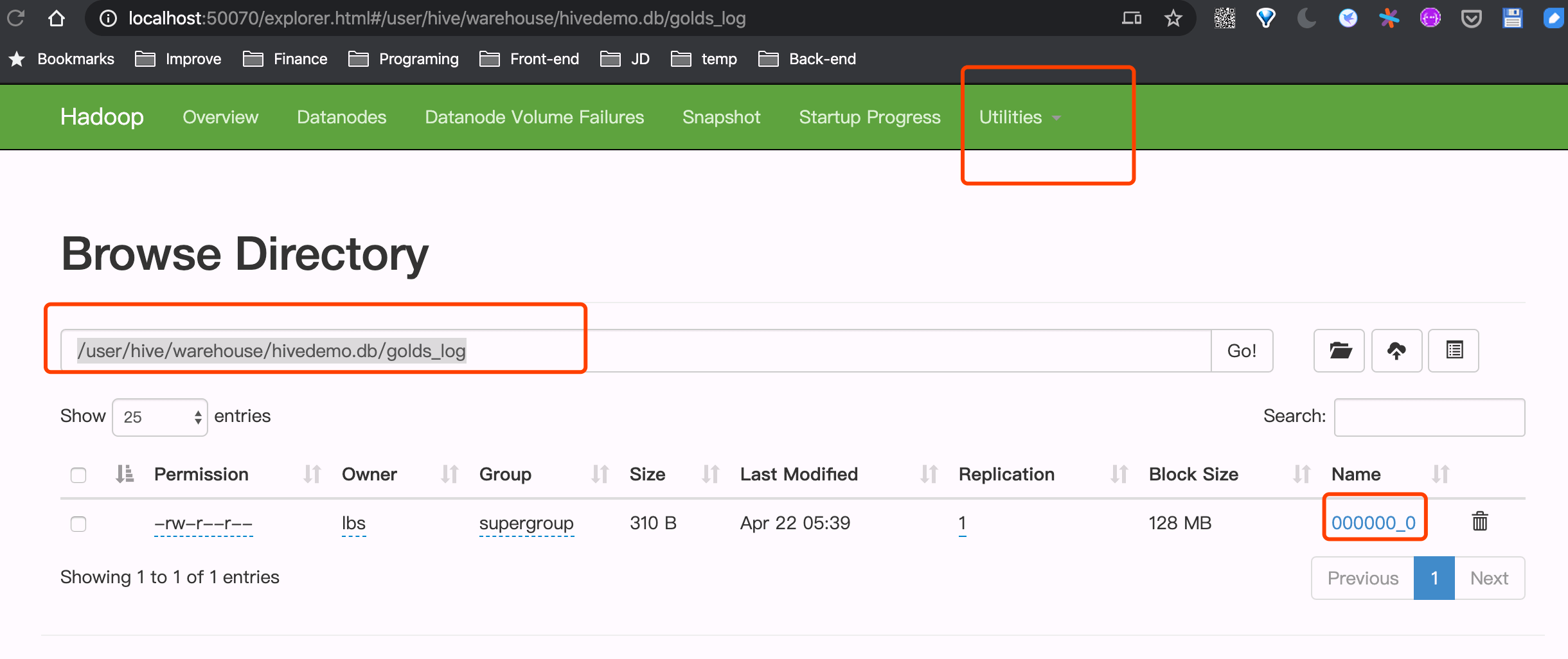
1 | 3645356 wds7654321(4171752) 新人注册奖励 1700 1526027152 |
000000_0文件是一个普通的文本文件(Hive中默认的文件存储格式),可以用 VSCode 打开。
- 继续执行2次
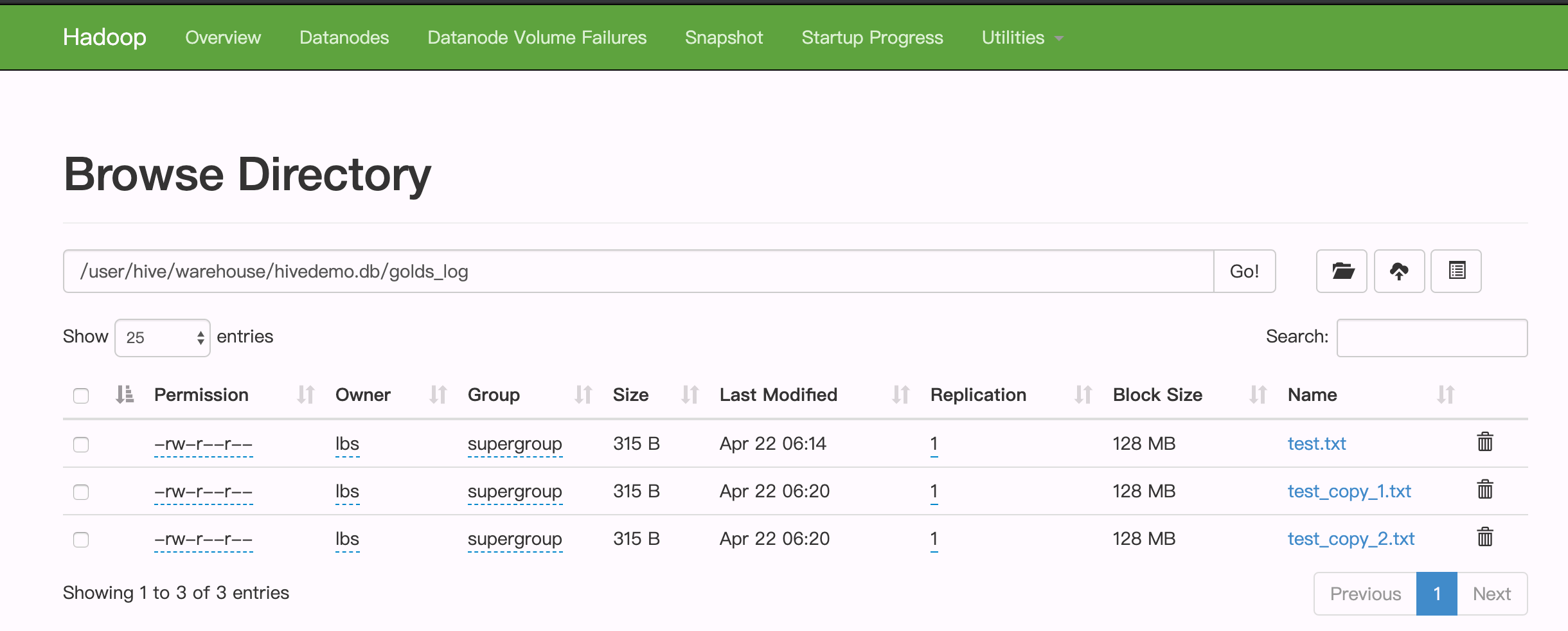
Insert...values命令,再次访问http://localhost:50070/explorer.html#/user/hive/warehouse/hivedemo.db/golds_log页面,可以发现有3个文件,即每次任务都生成了单独的数据文件。

Hive中,每次执行 Insert 语句(底层执行 MapReduce 任务)都会生成独立的数据文件。对于 HDFS 来说,优势是存储少量大文件,不是存储大量小文件。
而对于我们的应用而言,每 10 分钟就会同步一次数据到 Hive 仓库,如此一来会生成无数的小文件,系统的运行速度会越来越慢。所以第一个问题就是:如何合并小文件?
Demo-合并数据库小文件
在建表的时候,我们没有指定表存储的文件类型(file format),默认的文件类型是 Textfile,所以,当我们下载生成的 000000_0 文件后,使用编辑器可以直接查看其内容。
Hive 提供了一个 ALTER TABLE table_name CONCATENATE 语句,用于合并小文件。但是只支持 RCFILE 和 ORC文件类型。
因此,如果想合并小文件,可以删除表,然后再使用下面的命令重建
1 | hive> drop table golds_log; |
1 | hive> Create Table golds_log(user_id bigint, accounts string, change_type string, golds bigint, log_time int) |
1 | hive> Insert into table golds_log values |
重复上面的过程,执行 3 次 insert 语句,每次插入 5 条数据。刷新 WebUI,会看到和前面一样产生 3 个文件。
Tip: 如果此时再将
000000_0文件下载下来,用文本编辑器或者 VSCode 打开查看,发现已经是乱码了。因为它已经不再是文本文件了。
接下来,执行下面的语句,对文件进行合并
1 | hive> alter table golds_log concatenate; |
输出结果如下
1 | Starting Job = job_1587504428431_0006, Tracking URL = http://localhost:8088/proxy/application_1587504428431_0006/ |
刷新WebUI,会发现文件已经合并了,只有一个文件存在。
最后,使用 SELECT 语句查看数据表的内容。
1 | hive> select * from golds_log; |
Demo-Load 导入外部数据
下面给出一个实例,如何将本地数据文件 test.txt 导入到 Hive 数据表中。
- 本地数据文件
test.txt内容如下
1 | 3645356|wds7654321(4171752)|新人注册奖励|1700|1526027152 |
- 创建数据表,与本地
test.txt的数据类型一致
1 | hive> Create Table golds_log(user_id bigint, accounts string, change_type string, golds bigint, log_time int) |
上面最重要的一句就是 ROW FORMAT DELIMITED FIELDS TERMINATED BY '|',说明表的字段由符号 "|" 进行分隔。
Tip:
test.txt中包含有中文,确保文件格式是utf-8(GB2312导入后会有乱码)
- 查看数据表的结构
1 | describe golds_log; |
- 查看数据表内容(此时为空)
1 | select * from student1; |
- 导入本地数据
1 | hive> load data local inpath '/Users/lbs/Downloads/test.txt' into table golds_log; |
你会发现使用 load 语句写入数据比 insert 语句要快许多倍,因为 HIVE 并不对 scheme 进行校验,仅仅是将数据文件挪到 HDFS 系统上,也没有执行 MapReduce 作业。所以从导入数据的角度而言,使用 load 要优于使用 insert…values。
- 再次数据表内容
1 | hive> select * from golds_log; |
- 反复导入 3 次后,打开 Web UI,刷新后,发现和使用 Insert 语句时一样,每次 load 语句都会生成一个数据文件,同样存在小文件的问题。
和前面的方法一样,我们可以将表的存储类型改为 RCFile,然后再进行合并,但是因为使用 load 语句的时候,要导入的文件类型是 txt,和表的存储类型不一致,所以会报错。
这时候,只能曲线救国了:将主表创建为 RCFile 类型,再创建一张临时表,类型是 Textfile,然后 load 时导入到临时表,然后再使用下一节要介绍的 Insert...select 语句,将数据从临时表导入到主表。
Demo-使用 Insert…Select 语句写入数据
- 使用下面的语句创建一张临时表,临时表的名称为
golds_log_tmp。临时表在当前会话(session)结束后会被 HIVE 自动删除,临时表可以保存在SSD、内存或者是文件系统上。
1 | hive> Create TEMPORARY Table golds_log_tmp(user_id bigint, accounts string, change_type string, golds bigint, log_time int) |
- 使用下面的语句创建主表
1 | hive> drop table golds_log; |
1 | hive> Create Table golds_log(user_id bigint, accounts string, change_type string, golds bigint, log_time int) |
- 使用下面的语句将数据导入到临时表
1 | hive> load data local inpath '/Users/lbs/Downloads/test.txt' into table golds_log_tmp; |
- 使用insert…select语句将数据从临时表转移到主表
1 | hive> Insert into table golds_log select * from golds_log_tmp; |
需要注意的是,insert...select 语句底层也会执行一个 MapReduce 作业,速度会比较慢。
- 在多次执行
insert...select后,golds_log下仍然会生成多个小文件,此时,只要执行一下合并小文件的语句就可以了
1 | hive> alter table golds_log concatenate; |
Hive 数据查询
表操作
Hive的数据表分为2种:内部表和外部表
- 内部表:Hive创建并通过 LOAD DATA INPATH 进数据库的表,这种表可以理解为数据和表结构都保存在一起的数据表。当通过
DROP TABLE table_name删除元数据中表结构的同时,表中的数据也同样会从 HDFS 中被删除。 - 外部表:在表结构创建以前,数据已经保存在HDFS中,通过创建表结构,将数据格式化到表的结构里。当通过
DROP TABLE table_name操作的时候,Hive 仅仅删除元数据的表结构,而不删除HDFS上的文件。所以,相比内部表,外部表可以更放心地大胆使用。
- 创建表时,
LIKE允许用户复制现有的表结构,但不是复制数据
1 | LIKE existing_table_name |
- 创建表时,使用
EXTERNAL声明外部表
1 | CREATE EXTERNAL TABLE tablename IF NOT EXISTS tablename |
- 数据表在删除时候,内部表会连数据一起删除,而外部表只删除表结构,数据还是保留的。
1 | DROP TABLE table_name |
- 在表查询时候,使用
ALL和DISTINCT选项区分对重复记录的处理。默认是ALL,表示查询所有记录,DISTINCT表示去掉重复的记录。
1 | SELECT age, grade FROM table; |
- Hive 不支持
HAVING子句,可以将 HAVING 子句转化为一个子查询。
1 | //Hive 不支持 HAVING 子句 |
视图操作
视图 VIEW 是只读的,不支持 LOAD/INSERT/ALTER。可以使用 ALTER VIEW 改变 VIEW 定义
下面介绍下视图VIEW常见的操作语句
- 创建 VIEW
1 | CREATE VIEW [IF NOT EXISTS] view_name |
- 删除 VIEW
1 | DROP VIEW [IF EXISTS] view_name |
索引操作
索引是标准的数据库技术。Hive 0.7 版本之后支持索引。

