- 本文主要记录Mac下如何进行Hadoop伪分布模式安装,并通过词频统计Demo程序(WordCount)理解MapReduce的原理。
更新日志
- 2020/03/23,撰写
- 2020/03/28,添加《Hadoop 权威指南》阅读笔记
- 2020/03/29,添加《Hadoop 应用开发技术详解》阅读笔记
- 2020/04/21,添加 Hadoop 伪分布式配置
学习资料汇总
参考资料
《Hadoop权威指南》随书资料
- 随书源码:Source Code
- 随书数据集:Full Dataset
Hadoop基础
Hadoop和Spark
Hadoop和Spark是两种不同的大数据处理框架,如下图所示。

- 上图中的蓝色部分是Hadoop生态系统组件,黄色部分是Spark生态组件。
- 虽然它们是两种不同的大数据处理框架,但它们不是互斥的。Spark与Hadoop 中的 MapReduce 是一种相互共生的关系。
- Hadoop 提供了 Spark 许多没有的功能,比如分布式文件系统,而 Spark 提供了实时内存计算,速度非常快。
Hadoop 通常包括2个部分:存储和处理。存储部分就是Hadoop的分布式文件系统(HDFS),处理指的是MapReduce(MP)。
Hadoop 安装和配置
- ref-1:在Mac上配置Hadoop娱乐环境 | Blog
- ref-2:Mac OS X 上搭建 Hadoop 开发环境指南 | 知乎
- ref-3: Mac环境下Hadoop的安装与配置 | Segmentfault
Hadoop 安装模式
Hadoop 安装模式分为3种,分别是单机模式,伪分布模式和全分布模式。默认安装是单机模式。可以通过配置文件 core-site.xml,将默认的单机模式更改为伪分布模式。
关于Hadoop 3种安装模式和如何使用虚拟机进行分布式安装,可以参考《Hadoop应用技术详解》书籍的第2章节——Hadoop安装。
Hadoop 的运行方式是由配置文件决定的,因此如果需要从伪分布式模式切换回非分布式模式,需要删除
core-site.xml中的配置项。
下面简单记录,如何通过修改配置文件,在 Mac 上搭建伪分布模式 Hadoop 环境。
Hadoop 安装步骤
Hadoop的安装和配置步骤如下(具体细节参考上述参考链接)
- 安装Java。
- Mac设置中,进入“共享”设置页面,允许远程登录,使用
ssh localhost进行验证。 - 下载Hadoop源码,在 Hadoop官网 可下载,此处选择下载
hadoop 2.10.0。将下载的.tar.gz压缩包解压并放置到/Library/hadoop-2.10.0路径。 - 设置Hadoop环境变量
(1) 打开配置文件
1 | vim ~/.bash_profile |
(2) 设置环境变量
1 | HADOOP_HOME=/Library/hadoop-2.10.0 |
(3) 使配置文件生效,并验证Hadoop版本号
1 | source ~/.bash_profile |
- 修改 Hadoop 的配置文件
需要修改的 Hadoop 配置文件都在目录 etc/hadoop 下,包括
hadoop-env.shcore-site.xmlhdfs-site.xmlmapred-site.xmlyarn-site.xml
下面逐步进行修改
(1) 修改 hadoop-env.sh 文件
1 | export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_231.jdk/Contents/Home |
(2) 修改 core-site.xml 文件
设置 Hadoop 的临时目录和文件系统,localhost:9000 表示本地主机。如果使用远程主机,要用相应的 IP 地址来代替,填写远程主机的域名,则需要到 /etc/hosts 文件中做 DNS 映射。
1 | <configuration> |
(3) 修改 hdfs-site.xml 文件
hdfs-site.xml 指定了 HDFS 的默认参数副本数,因为仅运行在一个节点上(伪分布模式),所以这里的副本数为1。
1 | <configuration> |
(4) 修改 mapred-site.xml 文件
复制 mapred-site.xml.template 模板文件,并修改为 mapred-site.xml 文件,然后将 yarn 设置成数据处理框架,并设置 JobTracker 的主机名与端口。
1 | <configuration> |
(5) 修改 yarn-site.xml 文件
配置数据的处理框架 yarn
1 | <configuration> |
启动Hadoop
(1) 第一次启动Hadoop,需要对 NameNode 进行格式化,后续启动不再需要执行此步骤。
1 | hadoop namenode -format |
(2) 启动 HDFS:进入Hadoop 安装目录下的 sbin 目录,并启动HDFS(需要设置Mac允许远程登录,过程中共需要3次输入密码)
Tip: 初次安装和启动时,可以执行
./start-all.sh,进行必要的初始化安装
1 | cd /Library/hadoop-2.10.0/sbin |
若出现下述信息,表示启动成功
1 | lbsMacBook-Pro:sbin lbs$ ./start-dfs.sh |
需要注意的是,在log中会显示警告
1 | WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicabled的 |
上述提醒是关于 Hadoop 本地库的——Hadoop本地库是为了提高效率或者某些不能用Java实现的功能组件库。可以参考 Mac OSX 下 Hadoop 使用本地库提高效率 了解详情。
停止 Hadoop 方法如下
1 | cd /Library/hadoop-2.10.0/sbin |
(3) 在终端执行 jps,若看到如下信息,证明 Hadoop 可以成功启动。看到 DataNode,NameNode 和 SecondaryNameNode 信息,表明启动的是一个伪分布模式Hadoop。
1 | lbsMacBook-Pro:sbin lbs$ jps |
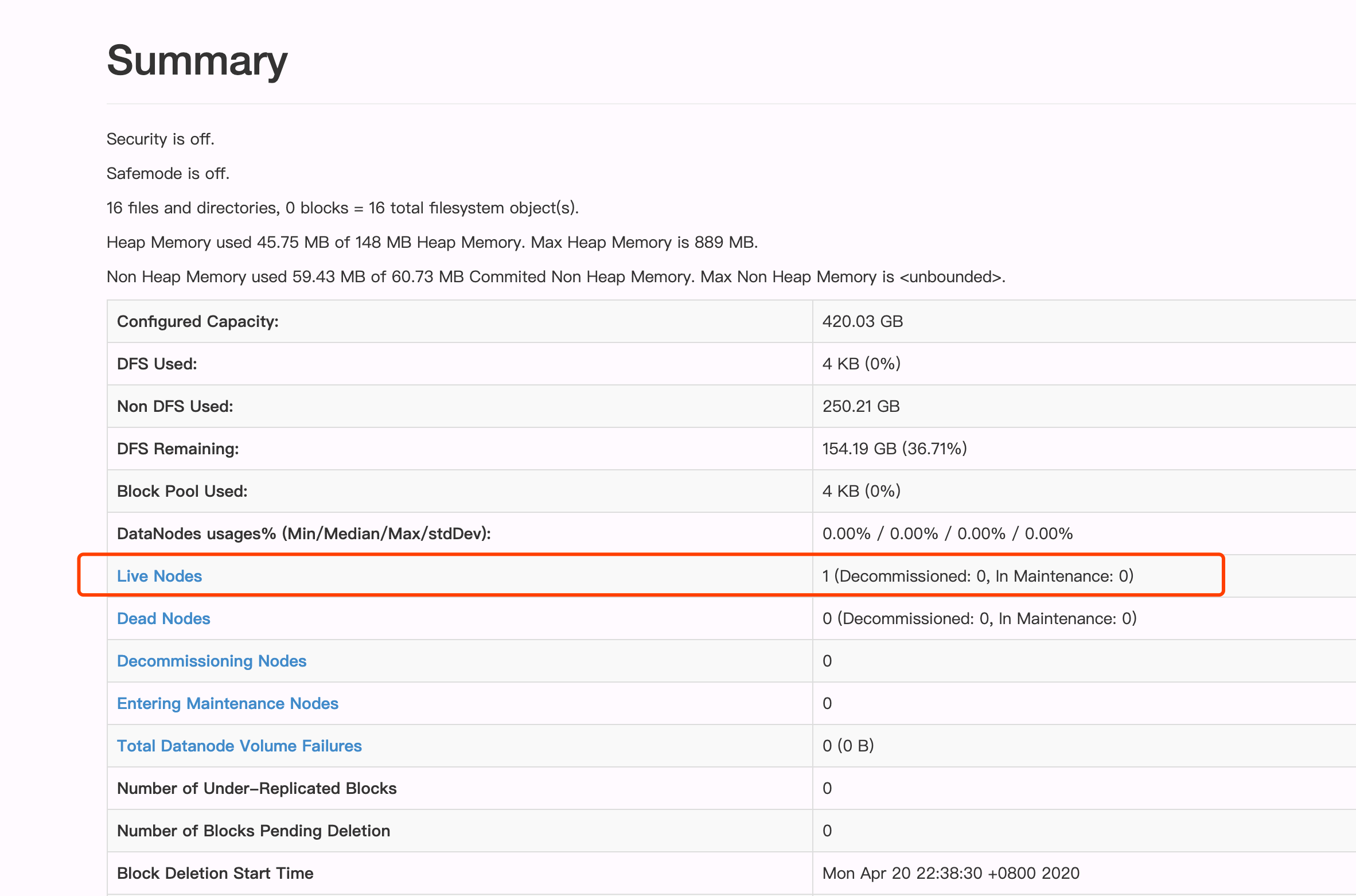
也可以访问 http://localhost:50070/dfshealth.html#tab-overview 来查看 Hadoop的启动情况。看到 Live Node 参数,证明伪分布模式 Hadoop 启动成功。
(4) 启动 yarn:进入Hadoop 安装目录下的 sbin 目录,并启动 yarn
1 | cd /Library/hadoop-2.10.0/sbin |
至此,Hadoop的安装,配置和启动就完成啦!接下来可以通过一些 shell 命令来操作 Hadoop 下的文件了,例如
1 | hadoop fs -ls / 查看根目录下的文件及文件夹 |
FAQ
Unable to load native-hadoop library for your platform
在启动 HDFS时,若看到如下警告
1 | ./start-dfs.sh |
1 | lbsMacBook-Pro:~ lbs$ cd /Library/hadoop-2.10.0/sbin |
上述提醒是关于 Hadoop 本地库的——Hadoop本地库是为了提高效率或者某些不能用Java实现的功能组件库。可以参考 Mac OSX 下 Hadoop 使用本地库提高效率 了解详情。
《Hadoop 应用开发技术详解》 学习笔记
MapReduce快速入门-WordCount
- Intellij 开发Hadoop环境搭建 - WordCount | 简书
- 使用IDEA编写第一个MapReduce程序
- Intellij结合Maven本地运行和调试MapReduce程序
- 一起学Hadoop——第一个MapReduce程序
工程创建
- 使用IDEA创建一个基于Maven的工程——WordCount
- 在
pom.xml中添加如下依赖
1 |
|
- 创建
WordMapper类
1 | package wordcount; |
- 创建
WordReducer类
1 | package wordcount; |
- 创建
WordMain驱动类
1 | package wordcount; |
IDEA中直接运行程序
选择 Run -> Edit Configurations, 在程序参数栏目中输入 input/ output,如下图所示

在 input 目录中添加统计单词个数的测试的文件 wordcount1.txt
1 | Hello,i love coding |
再次运行程序,会看到如下的 output 目录结构
1 | - input |
打开 part-r-00000 文件,即可看到单词出现次数的统计结果
1 | Hello, 1 |
需要注意的是,由于Hadoop的设定,下次运行程序前,需要先删除output文件目录。
导出jar包运行程序
- 在
File -> Project Structure选项中,为工程添加Artifacts,选择WordMain类


- 选择
Build -> Build Artifacts...,生成.jar文件
- 进入HDFS系统目录(不是其余文件系统目录),执行下述命令
1 | hadoop jar WordCount.jar input/ out/ |
HDFS分布式文件系统详解
认识HDFS
HDFS(Hadoop Distributed File System)是一个用在普通硬件设备上的分布式文件系统。 HDFS 具有高容错性(fault-tolerant)和高吞吐量(high throughput),适合有超大数据集的应用程序,可以实现通过流的形式访问文件系统中的数据。
运行在HDFS之上的应用程序必须流式地访问它们的数据集,它不是典型的运行在常规的文件系统之上的常规程序。HDFS的设计适合批量处理,而不是用户交互式的,重点是数据吞吐量,而不是数据访问的反应时间。
HDFS以块序列的形式存储每一个文件,文件中除了最后一个块的其他块都是相同的大小。
HDFS架构
HDFS 为Hadoop 这个分布式计算框架一共高性能,高可靠,高可扩展的存储服务。HDFS是一个典型的主从架构,一个HDFS集群是由一个主节点(Namenode)和一定数目的从节点(Datanodes)组成。
- Namenode 是一个中心服务器,负责管理文件系统的名字空间(
namespace)以及客户端对文件的访问。同时确定块和数据节点的映射。- 提供名称查询服务,它是一个 Jetty 服务器
- 保存
metadata信息,包括文件owership和permissions,文件包含有哪些块,Block保存在哪个DataNode等 - NameNode 的
metadata信息在启动后会加载到内存中
- Datanode一般是一个节点一个,负责管理它所在节点上的存储。DataNode 通常以机架的形式组织,机架通过一个交换机将所有系统连接起来。 DataNode的功能包括
- 保存Block,每个块对应一个元数据信息文件
- 启动DataNode线程的时候会向NameNode汇报Block信息
- 通过向NameNode发送心跳保持与其联系(3秒一次)
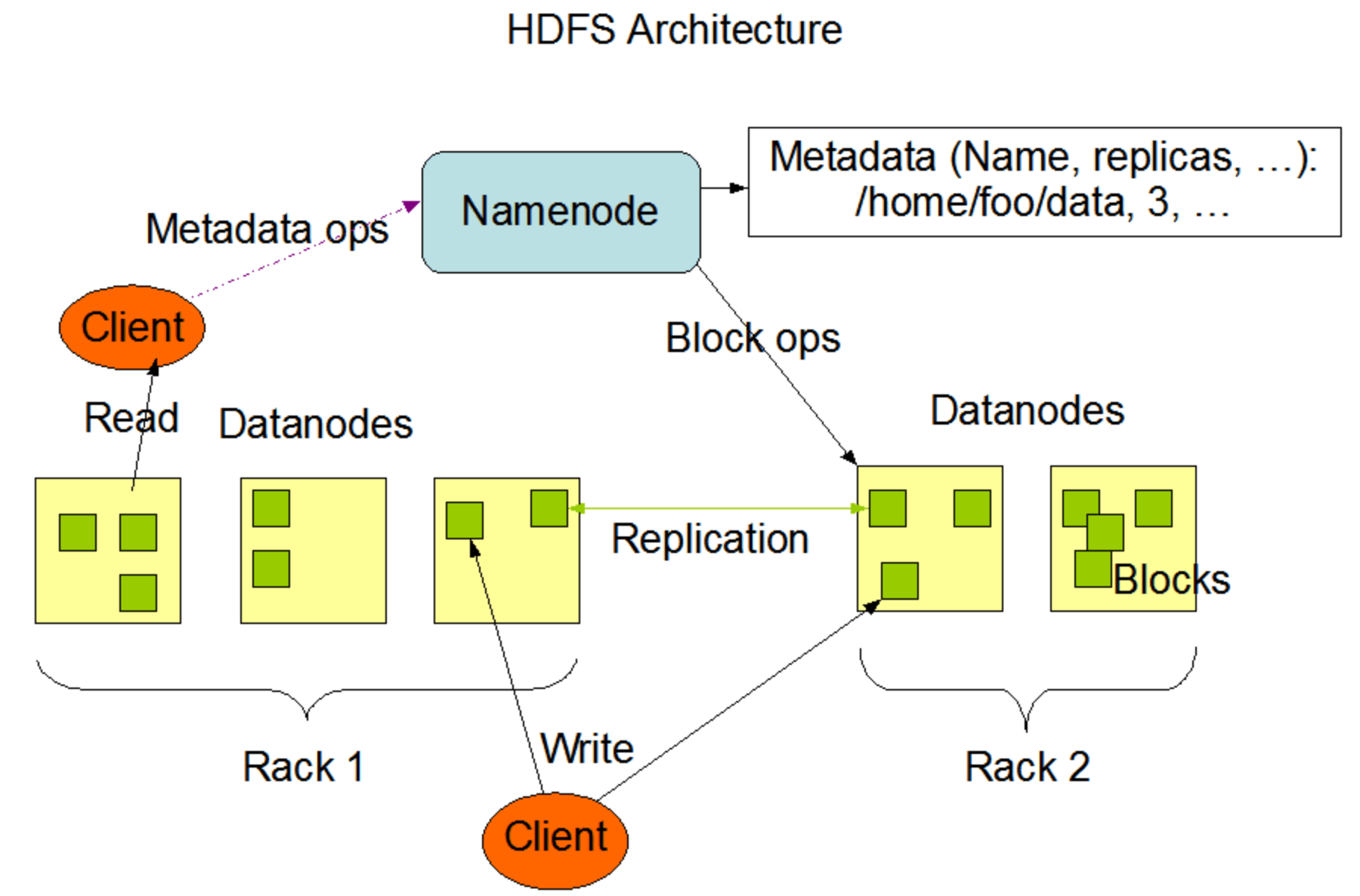
- 机架(
Rack):一个 Block 的三个副本通常会保存到两个或者两个以上的机架中,进行防灾容错 - 数据块(
Block)是 HDFS 文件系统基本的存储单位,Hadoop 1.X 默认大小是 64MB,Hadoop 2.X 默认大小是 128MB。HDFS上的文件系统被划分为块大小的多个分块(Chunk)作为独立的存储单元。和其他文件系统不同的是,HDFS上小于一个块大小的文件不会占据整个块的空间。使用块抽象而非整个文件作为存储单元,大大简化了存储子系统的设计。 - 辅助元数据节点(
SecondaryNameNode)负责镜像备份,日志和镜像的定期合并。
使用
hadoop fsk / -files -blocks可以显示块的信息。
Block 数据块大小设置的考虑因素包括
- 减少文件寻址时间
- 减少管理快的数据开销,因每个快都需要在 NameNode 上有对应的记录
- 对数据块进行读写,减少建立网络的连接成本
块备份原理
Block 是 HDFS 文件系统的最小组成单元,它通过一个 Long 整数被唯一标识。每个 Block 会有多个副本,默认有3个副本。为了数据的安全和高效,Hadoop 默认对3个副本的存放策略如下图所示
- 第1块:在本地机器的HDFS目录下存储一个 Block
- 第2块:不同 Rack 的某个 DataNode 上存储一个 Block
- 第3块:在该机器的同一个 Rack 下的某台机器上存储一个Block
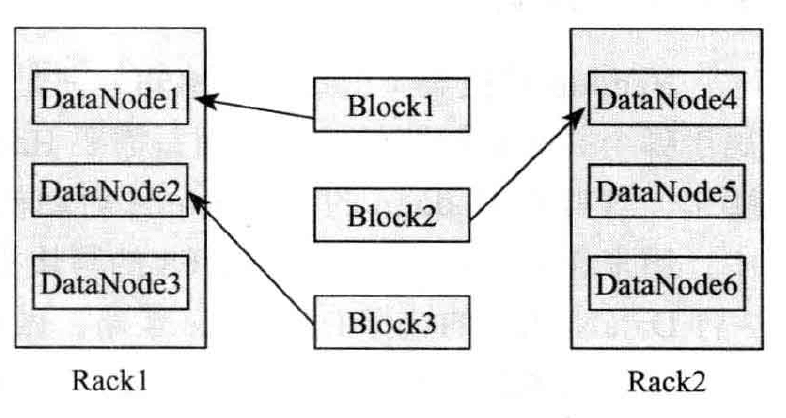
这样的策略可以保证对该 Block 所属文件的访问能够优先在本 Rack 下找到。如果整个 Rack 发生了异常,也可以在另外的 Rack 找到该 Block 的副本。这样足够高效,并且同时做到了数据的容错。
Hadoop的RPC机制
RPC(Remote Procedure Call)即远程过程调用机制会面临2个问题
- 对象调用方式
- 序列/反序列化机制
RPC 架构如下图所示。Hadoop 自己实现了简单的 RPC 组件,依赖于 Hadoop Writable 类型的支持。

Hadoop Writable 接口要求每个实现类多要确保将本类的对象正确序列化(writeObject)和反序列化(readObject)。因此,Hadoop RPC 使用 Java 动态代理和反射实现对象调用方式,客户端到服务器数据的序列化和反序列化由 Hadoop框架或用户自己来实现,也就是数据组装定制的。
Hadoop RPC = 动态代理 + 定制的二进制流
开源数据库HBase
Overview
- HBase 是一个可伸缩的分布式的,面向列的开源数据库,是一个适合于非结构化数据存储的数据库。需要注意的是,HBase 是基于列的而不是基于行的模式。
- 利用 HBase 技术可以在廉价 PC Server上搭建大规模结构化存储集群。
- HBase 是 Google Bigtable 的开源实现,与 Google Bigtable 利用GFS作为其文件存储系统类似, HBase 利用 Hadoop HDFS 作为其文件存储系统。Google 运行 MapReduce 来处理 Bigtable 中的海量数据,HBase 同样利用 Hadoop MapReduce 来处理海量数据。Google Bigtable 利用 Chubby 作为协同服务,HBase 利用 Zookeeper 作为对应。
HBase 的特点如下
- 大:一个表可以有上亿行,上百万列
- 面向列:面向列(族)的存储和权限控制,列(族)独立检索
- 稀疏:对于为空(NULL)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
Hadoop 实战Demo
有句话说得好,“大数据胜于算法”,意思是说对于某些应用(例如根据以往的偏好来推荐电影和音乐),不论算法有多牛,基于小数据的推荐效果往往都不如基于大量可用数据的一般算法的推荐效果。 —— 《Hadoop 权威指南》

